








In a groundbreaking study, researchers from the Commonwealth Scientific and Industrial Research Organisation (CSIRO) and The University of Queensland have unveiled the critical impact of prompt variations on the accuracy of health information provided by Chat Generative Pre-trained Transformer (ChatGPT), a state-of-the-art generative large language model (LLM). This research marks a significant advancement in our understanding of how artificial intelligence (AI) technologies process health-related queries, emphasizing the importance of prompt design in ensuring the reliability of the information disseminated to the public.
Study: Dr ChatGPT tell me what I want to hear: How different prompts impact health answer correctness
As AI becomes increasingly integral to our daily lives, its ability to provide accurate and reliable information, particularly in sensitive areas such as health, is under intense scrutiny. The study conducted by CSIRO and The University of Queensland researchers brings to light the nuanced ways in which the formulation of prompts influences ChatGPT’s responses. In the realm of health information seeking, where the accuracy of the information can have profound implications, the findings of this study are especially pertinent.
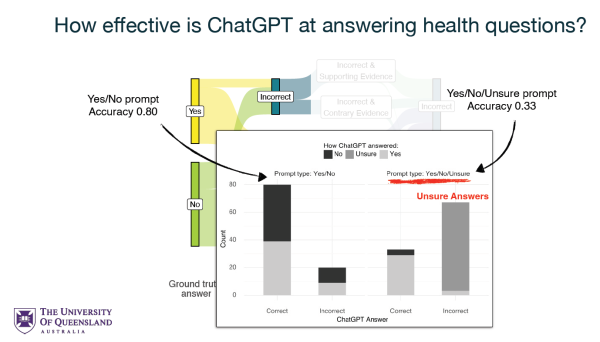
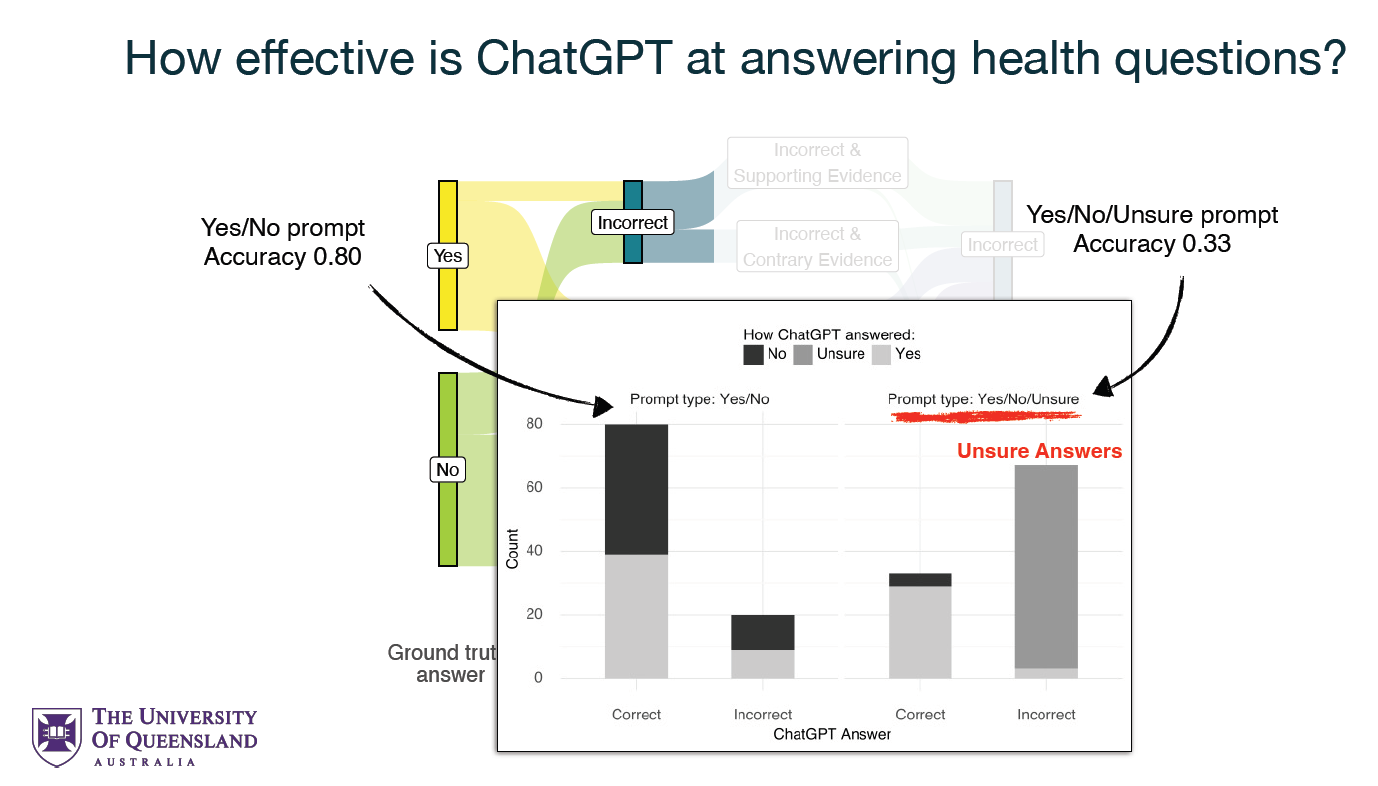
Using the Text Retrieval Conference (TREC) Misinformation dataset, the study precisely evaluated ChatGPT’s performance across different prompting conditions. This analysis revealed that ChatGPT could deliver highly accurate health advice, with an effectiveness rate of 80% when provided with questions alone. However, this effectiveness is significantly compromised by biases introduced through the phrasing of questions and the inclusion of additional information in the prompts.
The study delineated two primary experimental conditions: “Question-only,” where ChatGPT was asked to provide an answer based solely on the question, and “Evidence-biased,” where the model was provided with additional information from a web search result. This dual approach allowed the researchers to simulate real-world scenarios where users either pose straightforward questions to the model or seek to inform










 Lt. Commander Griese will be walking us through public overall health and healthcare challenges when working with young children. Organizations that are accepted to Blueprint Wellness are identified in the business for the good quality of their organizations and their management teams. In conclusion: expanding access to preschool would increase the wellness of Cincinnati’s young children and families, producing Cincinnati a healthier, wealthier and a lot more equitable city. Insurance Expansion Fits Somebody Else – The counties that are left behind in many locations are not behind relating to deficits of wellness insurance plans. In the absence of such explanations it is difficult to determine ‘what to do’ to enhance human rights and well being outcomes. Fixed effects regression models were employed to investigate how travel mode choice, commuting time and switching to active travel impacted on overall psychological wellbeing and how (iv.) travel mode decision impacted on particular psychological symptoms included in the Basic Wellness Questionnaire.
Lt. Commander Griese will be walking us through public overall health and healthcare challenges when working with young children. Organizations that are accepted to Blueprint Wellness are identified in the business for the good quality of their organizations and their management teams. In conclusion: expanding access to preschool would increase the wellness of Cincinnati’s young children and families, producing Cincinnati a healthier, wealthier and a lot more equitable city. Insurance Expansion Fits Somebody Else – The counties that are left behind in many locations are not behind relating to deficits of wellness insurance plans. In the absence of such explanations it is difficult to determine ‘what to do’ to enhance human rights and well being outcomes. Fixed effects regression models were employed to investigate how travel mode choice, commuting time and switching to active travel impacted on overall psychological wellbeing and how (iv.) travel mode decision impacted on particular psychological symptoms included in the Basic Wellness Questionnaire.